

- Published on
Diving deep into Mistral AI and their newest model, Mixtral-8x7B
- Authors
- Name
- Nathan Brake
- @njbrake


Meta AI: "Sunrise over the snowy mountains looking out over a lake that has a macbook in the distance and is floating slightly underneath the water, realistic"
Late last week there was an exciting announcement from the team at Mistral AI: they released the weights of their Mixtral-8x7B model and shared some information about it via their blog. This model outperforms both Llama2 and GPT-3.5 on several popular performance tests (see the below table). This is one of the first open models that can match ChatGPT (GPT-3.5) performance! This model also supports a context length of 32k tokens, which makes it useful for more complex tasks that require more tokens (e.g. summarization).
Performance of Mixtral as reported via https://mistral.ai/news/mixtral-of-experts/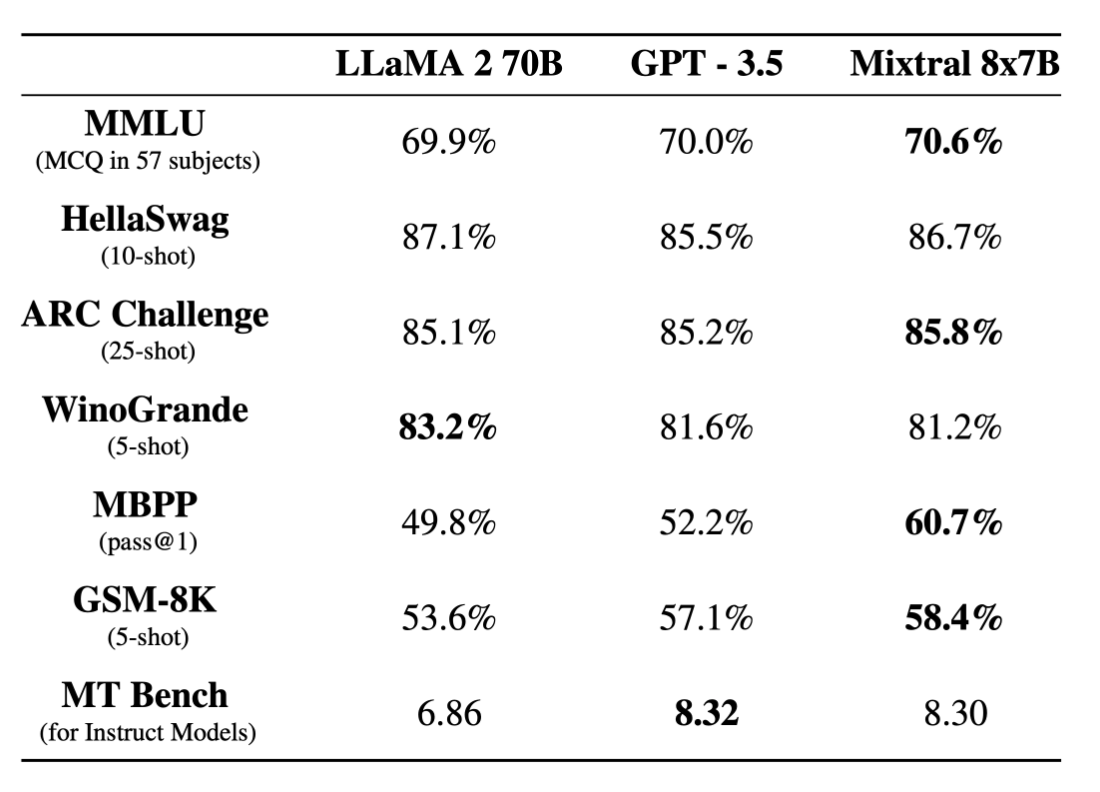
The Mixtral-8x7B model is built with the Mixture of Experts (MoE) architecture: this is rumored to be the design of GPT-4 since an OpenAI engineer posted about it on twitter. That post was quickly deleted but is summarized in this reddit thread here. The topic also comes up in this podcast episode between Lex Fridman and George Hotz, where George pretty confidently affirms that GPT-4 is a MoE model. Although George isn't an OpenAI employee, he generally knows what's going on in the tech world.
If you're wondering what all the Mixture of Experts model hype is about, you're in luck: The developers at huggingface (HF) wrote two excellent posts explaining Mixtral-8x7B and MoEs: First, this HF Blogpost about Mixtral explains the Mixtral-8x7B model. Then, this HF blogpost explaining Mixture of Experts goes into the details about what MoE is and why it's a useful design. Since those posts are written with great detail and are very readable, I'm not going to explain how Mixtral / MoE work. Skim through those posts and then come back here when you're ready 😆.
After reading those above blog posts, I was curious to answer the question "this is all well and good, but how exactly does it work at the code level?". In this post, I'm exploring the architecture of Mixtral in detail: I'll open up the source code in the 🤗 Transformers library and step through each part of the Mixtral neural network to understand the details of what makes it different from other models.
TL;DR: If you want to understand how any Huggingface model works, all you need to do is look up its model card here and find the folder it corresponds to here. Then with some knowledge of Python and PyTorch, you can understand how any neural network is designed.
Mixtral Architecture
Mixtral is a variant of a decoder-only (auto-regressive) transformer (The same base architecture as most all LLMs like ChatGPT/GPT-4). The architecture of Mixtral is located in the 🤗 Transformers repository here.
The major building blocks of an auto-regressive transformer are shown in the below list. In order to construct this list of layers, I consulted the Initializer for Mixtral Model via Source Code and fill in the values using the config from the HF Model Card for Mixtral-8x7B-v0.1.
Main Components
These components are ordered as they would be invoked during a forward pass of the neural network.
- Word Embedding Layer (32,000, from vocab_size)
- DecoderLayers (12 layers, from num_hidden_layers)
- Input Layer Normalization Block (Dimension of 4096, from hidden_size)
- Self-Attention block (32 heads, from num_attention_heads)
- Post-Attention Layer Normalization Block (Dimension of 4096, from hidden_size)
- Sparse MoE block (8 experts, from num_local_experts, 2 experts per token, from num_experts_per_tok)
- Normalization Layer (Dimension of 4096, from hidden_size)
- Final Linear Layer. This is technically a part of the MixtralForCausalLM model, not the MixtralModel itself but I'll include it here just for completeness. This linear layer takes the output from the 4096-dim Normalization layer and outputs the logits (32,000, the size of the vocabulary) for causal language modeling. If you don't understand what this means, I can't recommend enough this video by Andrej Karpathy.
Now time to dive deep on each part of this architecture! I'm going to skip over describing layer normalization blocks in general, but I will say that the Mixtral/Mistral LayerNorm is basically the same as the T5 layer norm here.
Embedding Layer
The embedding layer consists of word embeddings.
During the forward pass of the Mixtral model it gets invoked here. If you've looked at transformer models before you might have been expecting to see a positional embedding layer here as well: Mixtral uses rotary positional embeddings (RoPE), which mean that there isn't a positional embedding layer. Position ids are assigned here but not used until after the KQV projection in the attention layers here.
Decoder Layer
The decoder layer is here. Based on which GPU you're using, Mixtral conditionally uses FlashAttention2, which is a recent development this year that improves GPU memory management and efficiency to enable some massive speedups and memory savings (paper).
Self-Attention
A few interesting things about the Self-Attention block. First, Mixtral is using a sliding attention window, which was published via Longformer and Generating Long Sequences with Sparse Transformers. The "Generating Long Sequences with Sparse Transformers" paper was published by OpenAI back in 2019.
Second, as I mentioned earlier, Mixtral uses RoPE (paper) which allows for flexibility of sequence length and improved training convergence speed. The code for RoPE in Mixtral is copied from Llama. You will notice comments like this throughout the modeling_mixtral.py code:
# Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding with Llama->Mixtral
SparseMoeBlock
Finally, we get to the part of the Mixtral architecture that makes it special! Per the documentation, the MixtralSparseMoeBlock "is strictly equivalent to standard MoE with full capacity (no dropped tokens). It's faster since it formulates MoE operations in terms of block-sparse operations to accomodate imbalanced assignments of tokens to experts, whereas standard MoE either (1) drop tokens at the cost of reduced performance or (2) set capacity factor to number of experts and thus waste computation and memory on padding."
Breaking it down, the Sparse Moe block has two subcomponents.
Gating
The gating layer is a Linear layer responsible for being trained to route a token to the correct experts. As mentioned earlier, the Mixtral-8x-7B model has 8 experts and each token is routed to 2 of them.
Experts
This subcomponent is a list of 8 (8 experts) MixtralBLockSparseTop2MLP blocks.
Each MixtralBLockSparseTop2MLP is comprised of 3 linear layers and an activation function, which is a SiLU (Via the config). The SiLU is a Sigmoid Weighted Linear Unit (paper) and is the activation function designed to work well with Reinforcement Learning techniques.
With all the other components of Mixtral, the operation during a forward pass of the network is pretty clear. However, it wasn't clear to me how the SparseMoeBlock would work, so I decided to look at the forward pass of the SparseMoeBlock more closely.
Forward Pass Functionality
The code for the forward pass is here.
Extract the router logits (value between 0 and 1 of which expert is preferred by each token) by passing the hidden_state through the gating function.
Turn those logits into a probability distribution by passing them through a softmax function.
Select the top 2 highest probability experts for each token in the sequence from the choice of the 8
Loop over each of the 8 experts
a. Use a mask to filter out which tokens did not select that expert
b. Apply that expert (the 3 linear layers and SiLU function ) to that filtered list of tokens. There are some really nifty uses of pytorch here, especially the tensor.indexadd function
In all that logic, there is only a single for loop, everything else is accomplished by reshaping and adding matrices. Very cool. Even though there are 8 experts, each token only uses 2 of them, which means that by training the gating layer and each expert appropriately, you're able to get the performance of a larger network ( 8 experts * 3 linear layers = 24 linear layers) while only requiring the compute calculations of a much smaller network (2 experts). Note that all 8 experts are loaded into memory though, so the memory resources required is still quite high, but the computation part is where the efficiency is gained.
In order to stabilize this training process, there is also a loss function added to encourage the gating function to distribute tokens across the experts evenly so that each expert is trained. This notion (and the MoE design in general) is related to the Switch Transformer (paper). The paper was published by Google researchers, but as of 12/14/23, 2 of the 3 publishers now work at OpenAI. Might be another hint that the claims of GPT-4 being a MoE model are not far off.
Conclusion
Although we don't have much knowledge of how the Mixtral-8x7B model is trained, the MoE design is clearly what sets it apart from its predecessor, Mistral-7b. The long context length support and high performance relative to GPT-3.5 and Llama2-70b are a promising sign for future developments with MoE style models! Additionally, there will probably be plenty of people who think that 8x7B means that this model is 8 Mistral models stacked together, but now that we looked at the source code it's clear this is not the case.
Disclaimer
This is my analysis of Mixtral and my understanding may not be 100% correct: feel free to reach out if you see something I missed!