

- Published on
Find and Transcribe iMessage Voice Memos
- Authors
- Name
- Nathan Brake
- @njbrake


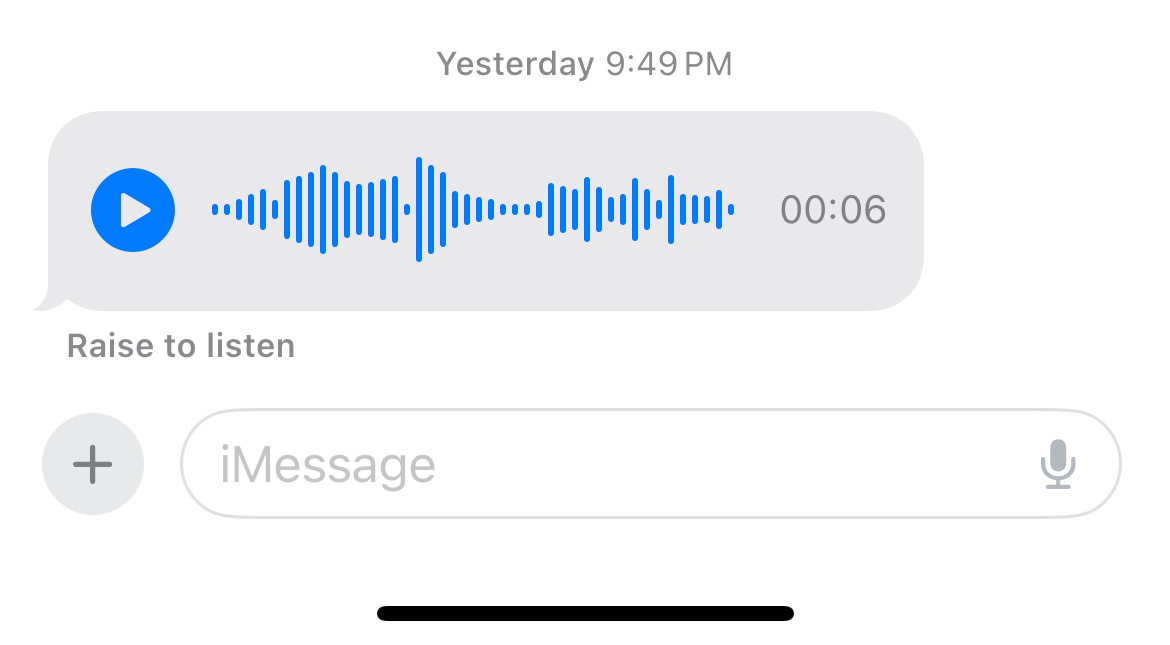
Introduction
Voice memos. They're so easy to send, and unlike using the voice-to-text feature of iPhone, you don't have to worry about looking over the output because you trust the other person will understand what you're saying when they listen to your audio. This is convenient for the sender of the message, not so much for the person receiving it. Unlike the phone voicemail in iOS, Apple decided not to provide the recipient of these voice memos with so much as a draft transcript of the message content.
If it's just a few seconds of audio that's no problem, but what about when the voice message is multiple minutes long? If I'm in a meeting or on another call, I'd like to be able to know the content of the audio before I have the time to listen to it. What if there was a way to grab the audio file and send it through an ASR pipeline on my own, since Apple doesn't want to do it for me?
On iOS unfortunately I'm kind of stuck: it's a closed operating system and I don't have much hope of exploring and accessing the iPhone filesystem to get the files. However, I have a Macbook, and there is an iMessage app on the mac that receives those audio messages too. That means that the audio files are sitting somewhere in my Mac, all we need to do is find it and then we're golden!
In this blog post I'll explain how to load your iMessage chat & data using python, and how to run this through a distilled version of the popular OpenAI Whisper speech recognition system.
Here's what it looks like to run the program and transcribe a short voice memo I recorded:
$ python audio-imessage.py
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
------------ The Latest Audio Message from +1________ ------------
This is a voicemail that I sent to myself.
---------------------------------------------------
Technology
iMessage
From this very helpful blog post, I learned that all iMessage information is stored in a SQL database located in a user's home directory at ~/Library/Messages/chat.db. That blog post was specifically dealing with how to access text messages so it didn't directly tell me how to find the audio files, but it gave me the base toolset to explore the SQL db and find the data I was looking for.
Automatic Speech Recognition (ASR)
Although in a previous role at 3M I was involved with speech recognition, I'm still curious to stay up-to-date on developments in ASR. Although work in Natural Language Understanding (NLU) isn't directly handling audio (unless the model is multi-modal), it can still be closely related to ASR for scenarios where processing of natural language is being done for text coming from an ASR system.
I'm aware of the hype around OpenAI's Whisper model here that was released in 2022. Although its accuracy was impressive, the model is 764M parameters, the weights take a little over 3GB of space to download, and I worried about a slow inference time on my laptop CPU.
Then, earlier this month (Nov 1 2023) a paper was published by the folks at Huggingface documenting their work on Distil-Whisper. It's a distilled model of whisper (What is Knowledge Distillation?) that has 51% fewer parameters and is reported to be 5.8 times faster than the original Whisper model. The distil-whisper model page has some more info about different ways to use the model. For the sake of simplicity we will use the huggingface pipeline class and follow the recommended distil-whisper implementation for Long-Form Transcription.
Code Walkthrough
I provide the entire python code in a single snippet at the end. This code will find the most recent audio message, run it through ASR, and print the text output. The script will take as an optional input a phone number, otherwise it will run ASR over whatever audio message you most recently received. Note that the Apple iMessage Voice Memo feature deletes the voice memos after they have been listened to, so this only works when you haven't yet listened to the voice memo. Of course this isn't a problem for me because the whole reason I'm doing this is so that I don't have to listen to the voice memo 😆.
At the end you will be able to run the python script from a bash terminal like
python audio-imessage.py --phone_number +11234567890
Pre-Requisites
You will need to be running on MacOS, with your iCloud account connected and iMessage configured so that you are receiving iMessages in a way that they can be viewed from the "Messages" app on your Mac.
- You need to have ffmpeg installed: instructions
- You need python3-pip installed
- Install these python3 dependencies
python3 -m pip install transformers==4.35 accelerate ffmpeg-python pandas
All the code in a single snippet
Instead of having individual snippets, I'll put all of the code into a single block, and add comments to explain what's happening.
If you would like to run it, feel free to copy and paste the below into a python file for yourself.
# Import all the packages that we need
import argparse
import os
import sqlite3
from tempfile import mkdtemp
import pandas as pd
import datetime as datetime
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
import ffmpeg
# Programmatically determine the home directory path e.g. /Users/nathanbrake
USER_HOME = os.path.expanduser("~")
def main(args):
"""
This blog post was helpful as a starting point for how to access the iMessage database:
https://medium.com/@yaskalidis/heres-how-you-can-access-your-entire-imessage-history-on-your-mac-f8878276c6e9
"""
# Connect to the SQL db that has all the iMessage data
conn = sqlite3.connect(f"{USER_HOME}/Library/Messages/chat.db")
# Get all the messages from the db 'message' table and also create a column called 'date_uct' that will be used for sorting later
messages = pd.read_sql_query(
"""select *, datetime(message.date/1000000000 + strftime("%s", "2001-01-01") ,"unixepoch","localtime") as date_uct from message""",
conn,
)
# turn the date_utc into a pandas time object so that we can use that for sorting
messages["timestamp"] = pd.to_datetime(messages["date_uct"])
# Get all the data from the 'handle' table which has the phone_number data that we need to match a message with a person
handles = pd.read_sql_query("select * from handle", conn)
# rename the columns to something meaningful so that the ROWID column doesnt clash between the two sql results
chat_message_joins = pd.read_sql_query("select * from chat_message_join", conn)
messages.rename(columns={"ROWID": "message_id"}, inplace=True)
handles.rename(columns={"id": "phone_number", "ROWID": "handle_id"}, inplace=True)
# merge the two sql results together so now there is a pandas dataframe that has the phone_number and message content in a single row
df_messages = pd.merge(
pd.merge(
messages[messages.columns],
handles[["handle_id", "phone_number"]],
on="handle_id",
how="left",
),
chat_message_joins[["chat_id", "message_id"]],
on="message_id",
how="left",
)
# If the user requested an audio message from a specific phone number, filter out and remove all other messages
if args.phone_number is not None:
print(f"Searching for messages from {args.phone_number}")
df_messages = df_messages[df_messages["phone_number"] == args.phone_number]
# sort by timestamp, newest first
df_messages = df_messages.sort_values(by=["timestamp"], ascending=False)
def get_audio_message(df_messages):
for _, row in df_messages.iterrows():
# From examining the data, I found that for voice memos,
# the attributedBody column had a base64 encoded string that had a GUID that I could look for
# in the ~/Library/Messages/Attachments directory! This took some sleuthing
url_l = row["attributedBody"]
if url_l is None:
continue
url_l = url_l.decode("utf-8", "ignore")
# the attributedBody column can have content that isn't always a file... so look for the specific keyword.
if "FileTransferGUIDAttributeName" not in url_l:
continue
# This also took some sleuthing, looking at some values and figuring out how to split up the big string into just the GUID
# That macOS was using to index the files inside of the Attachments directory
guid = (
str(url_l.split("FileTransferGUIDAttributeName$")[1].split("_")[0])
.strip()
.replace("&", "")
)
# walk through all the directories to find the folder in ~/Library/Messages/Attachments/ that has that guid
for root, dirs, files in os.walk(
f"{USER_HOME}/Library/Messages/Attachments/"
):
for direct in dirs:
if guid in direct:
# print out the full path
# list out the files inside of root/direct
files = os.listdir(os.path.join(root, direct))
for file in files:
if "Audio Message" in file:
return (
os.path.join(root, direct, file),
row["phone_number"],
)
raise Exception("No audio messages found")
audio_file_path, number = get_audio_message(df_messages)
# get a tmp dir using mkdtemp
tmp_file = os.path.join(mkdtemp(), "sound.wav")
ffmpeg.input(audio_file_path).output(tmp_file).overwrite_output().run(quiet=True)
"""
Using Distil-Whisper model from https://huggingface.co/distil-whisper/distil-medium.en
The below is directly copied and pasted from the huggingface page but I'll add in some comments
"""
# This isn't relevant for us since we're running on macOS. Theoretically at some point they might add support for the mac
# ML accelerator ( the 'MPS' chip) but until then this will have to run on the mac CPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# The distil-whisper model has two different sizes available with different model weight data types being used.
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-medium.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
# This makes our life so easy. The huggingface pipeline takes care of all of the code that would need to load/tokenize/extract the
# audio and run ASR on it.
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=15,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
result = pipe(tmp_file)
# delete tmp_dir
os.system(f"rm -rf {tmp_file}")
return result["text"], number
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--phone_number",
"-p",
default=None,
type=str,
help="Phone number to search for",
)
args = parser.parse_args()
result, number = main(args)
print(f"------------ The Latest Audio Message from {number} ------------")
print(result)
print("-----------------------------------------------------------------")
I hope that this this sparks your curiosity into finding other fun ways you might be able to piece together tools that are readily available to do something useful!